
Page 599 - NEIC_FINAL REPORT
P. 599
โครงการศึกษาการจัดทําแผนยุทธศาสตร์และออกแบบการพัฒนาศูนย์สารสนเทศ
พลังงานแห่งชาติเพื่อรองรับการใช้ข้อมูลขนาดใหญ่ (Big Data) ในการขับเคลื่อน
แผนพลังงานของประเทศไทย
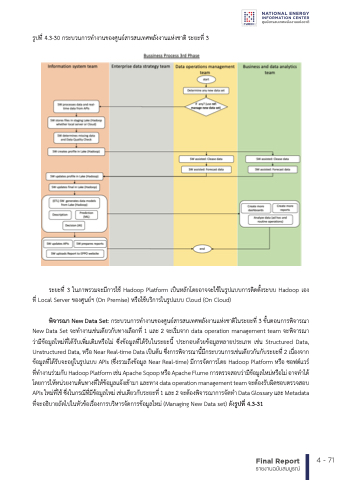
รูป็ทั้้ 4.3-30 กระบวนการทั้าํา งานข้องศึูนย์สำารสำนเทั้ศึพัลังงานแหังช้าติ ระยะทั้้ 3 รายงานฉบับสมบูรณ์
รูปที่ 4.3-29 กระบวนการทํางานของศูนย์สารสนเทศพลังงานแห่งชาติ ระยะท่ี 3
ระยะทั้้ 3 ในภาพัรวมูจะมู้การใช้้ Hadoop Platform เป็็นหัลักโดยอาจจะใช้้ในรป็ู แบบการติดตังระบบ Hadoop เอง
ทั้้ Local Server ข้องศึูนย์ฯ (On Premise) หัร้อใช้้บริการในรูป็แบบ Cloud (On Cloud)
ระยะที่ 3 ในภาพรวมจะมีการใช้ Hadoop Platform เป็นหลักโดยอาจจะใช้ในรูปแบบการติดตั้งระบบ
Hadพัoิจoาpรณ์เอางทNี่eLwocDaaltSaeSrveetr: กขรอะงบศวูนนยก์ฯาร(Oทั้nําางPาrนeข้mองisศึeูน)ยห์สำราือรใสำชน้บเรทั้ิกศึาพัรลในังงราูปนแบหับงช้Cาlตoิใuนdระ(Oยะnทั้C้ 3loข้uันdต)อนการพัิจารณา
New Data Set จะทั้ําางานเช้นเด้ยวกับทั้างเล้อกทั้้ 1 และ 2 จะเริมูจาก data operation management team จะพัิจารณา
วามู้ข้้อมููลใหัมูทั้้ได้รับเพัิมูเติมูหัร้อไมู ซึ่ึงข้้อมููลทั้้ได้รับในระยะน้ ป็ระกอบด้วยข้้อมููลหัลายป็ระเภทั้ เช้น Structured Data,
พิจารณา New Data Set: กระบวนการทํางานของศูนย์สารสนเทศพลังงานแห่งชาติในระยะที่ 3
UnstructuredData,หัร้อNearReal-timeDataเป็็นต้นซึ่ึงการพัิจารณานมู้ ้กระบวนการเช้นเด้ยวกันกับระยะทั้้2เน้องจาก
ขั้นตอนการพิจารณา New Data Set จะทํางานเช่นเดียวกับทางเลือกที่ 1 และ 2 จะเริ่มจาก data operation
ข้้อมููลทั้ไ้ด้รับจะอยูในรูป็แบบAPIs(ซึ่ึงรวมูถึงข้้อมููลNearReal-time)มูก้ารจัดการโดยHadoopPlatformหัรอ้ ซึ่อฟต์แวร์
management team จะพิจารณาว่ามีข้อมูลใหม่ที่ได้รับเพิ่มเติมหรือไม่ ซึ่งข้อมูลที่ได้รับในระยะนี้ ประกอบด้วย
ทั้ทั้้ ําางานรว มูกบั Hadoop Platform เช้น Apache Sqoop หัรอ้ Apache Flume การตรวจสำอบวา มูข้้ อ้ มูลู ใหัมูหั รอ้ ไมู อาจทั้ําาได้
ข้อมูลหลายประเภท เช่น Structured Data, Unstructured Data, หรือ Near Real-time Data เป็นต้น
โดยการใหัหั้ นว ยงานตน้ ทั้างทั้ใ้ หัข้้ อ้ มูลู แจง้ เข้า้ มูา และทั้าง data operation management team จะตอ้ งรบั ผดิ ช้อบตรวจสำอบ
APIsซใึ่งหักมูาทั้รพ้ใช้ิจ้ ซึ่ารึงใณนากนรณ้ีมีก้ทั้รมู้ ะ้ข้บ้อวมูนูลกใหัารมูเชเช้่นนเเดีย้ยวกันับกระับยระทั้ย้ะ1ทแ่ี ล2ะเ2นื่อจงะจตา้อกงขพั้อิจมารูลณทาี่ไกดา้รรับจจัดะทั้อาํา ยDู่ในatรaูปGแlบoบssaArPyIsแล(ซะึ่งMรวeมtaถdึงata
ทั้้จะอธิบายถัดไป็ในหััวข้้อเร้องการบริหัารจัดการข้้อมููลใหัมู (Managing New Data set) ดังรูปัที่่ 4.3-31
ข้อมูล Near Real-time) มีการจัดการโดย Hadoop Platform หรือ ซอฟต์แวร์ที่ทํางานร่วมกับ Hadoop
Platform เช่น Apache Sqoop หรือ Apache Flume การตรวจสอบว่ามีข้อมูลใหม่หรือไม่ อาจทําได้โดยการ ให้หน่วยงานต้นทางที่ให้ข้อมูลแจ้งเข้ามา และทาง data operation management team จะต้องรับผิดชอบ
4.3-67
Final Report
รายงานฉบับสมบูรณ์
4 - 71
